
Machine Learning Engineer Vs. AI Engineer: Which One to Choose?
Your ultimate guide to mastering ML/AI

AI is making headlines, data scientists with profound machine learning knowledge are upskilling to become AI engineers, but does that make machine learning engineers less valuable? I’ve been doing both things for 5 and 3 years respectively and in this post, I’m going to break down the difference, offering step-by-step roadmap on how to upskill in both.
Most people think that machine learning and AI engineering are the same, but AI engineer is a much broader field. Machine learning engineers are usually data scientists who absolved some parts of the engineering process and lifecycle so they’d know how to deploy and manage ML systems in production.
However, AI engineers are also pioneers at software development, hence they know not only how to program and build, but also design, conceptualize and manage the whole development process of apps built on top of modern AI models.
So, let’s break it down!
3,000+ people have used this exact path to land roles at Google, Anthropic, and Airbnb. Get the full AI Engineer Roadmap
The Core Difference
AI is the philosophy of building intelligent systems that reason and complete tasks independently from humans. ML is a set of processes and algorithms that train future AI systems.
This is what they teach at school, but for many people, it’s confusing because they both work with AI.
Data is the ultimate product that makes both machine learning and modern AI systems possible. That’s why we’re centering on the definition towards data. Thanks to data, machine learning can build the intelligence AI systems use.
AI engineers build smart products that use intelligence obtained from data. If you’ve ever taken a class from database design and development, then you’ve probably heard of this “data helps build information, information helps build knowledge.”
A machine learning engineer is focused on creating the model itself. They take raw data, clean it, engineer features, train models, evaluate performance, and optimize until the predictions are reliable. Their world revolves around improving how well the model learns and performs.
An AI engineer, on the other hand, is focused on what happens after the intelligence already exists. They take models, often pre-trained ones like LLMs, and build systems around them. They design how users interact with the model, how data flows through the system, how responses are generated, and how everything performs in real time.
This leads to a deeper distinction:
· Machine learning is model-centric.
AI engineering is system and product-centric.
· ML engineers ask: how can I make this model more accurate?
AI engineers ask: how can I make this system useful, reliable, and scalable for real users?
The clearest way to think about it: ML Engineers create the tools. AI Engineers use the tools to build things.
Neither is more legitimate than the other. They demand different skills, attract different personalities, and open different career doors. The biggest mistake people make is treating AI Engineering as “easier ML Engineering” — it’s a different discipline, not a watered-down version.
Salary ranges & job market reality
Compensation varies heavily by company stage, location, and specialization — but here’s an honest picture as of 2025–2026.
ML Engineers at mid-level (2–4 years) typically earn $140,000–$180,000 in the US, with senior roles at top-tier tech companies reaching $200,000–$300,000+ including equity. The floor is lower than AI Engineering right now, but the ceiling is just as high, and the role is far more established.
AI Engineers are commanding a premium in the current market because demand dramatically outpaced supply when LLMs went mainstream. Mid-level roles sit at $160,000–$210,000, with senior AI engineers at well-funded AI startups frequently exceeding $250,000. This premium may compress as the talent pool grows.
Outside the US, both roles pay significantly less in absolute terms but are growing fast. European markets (Germany, Netherlands, UK) are competitive for ML Engineering. AI Engineering is concentrated in major tech hubs but remote roles are widespread.
The most important thing to understand about the job market right now: AI Engineering roles are multiplying faster, but ML Engineering roles are more stable and less subject to hype cycles. If you want to get hired quickly, AI Engineering has more open doors. If you want a role that’s resilient to market shifts, ML Engineering has a longer track record.
Both paths lead to the same ceiling. The difference is the route.
Day in the Life: Machine Learning Engineer
You start your day the same way you usually do, by checking the health of the systems you’ve already built.
One of your models, a fraud detection system you deployed a few months ago, is throwing a drift alert. Something changed overnight. The incoming data no longer looks like what the model was trained on. You don’t panic, but you know this is exactly how models silently break in production. You flag it and start digging.
Soon after, you’re in a call with the data engineering team. A feature pipeline has been dropping records again. It sounds simple on paper, but fixing it means changing an upstream schema, which means coordination, dependencies, and waiting. This is the part nobody talks about when they imagine “building models.”
Once you finally get into your notebook, things feel more familiar. You run experiments, tweak features, test different configurations. A new set of behavioral features improves your churn model, but only slightly, and it introduces overfitting. You try regularization, rerun everything, compare metrics again. Progress is incremental, not magical.
Later, during a code review, you catch a subtle but critical issue. Data leakage. Future information sneaking into the training set. Left unnoticed, it would have made the model look perfect in testing and fail in reality. These are the quiet wins of the job.
By the end of the day, you’re not building something new. You’re documenting what went wrong, scheduling a retrain, updating pipelines, and making sure the system stays reliable. You might even touch infrastructure, updating the inference service to handle a new schema.
That’s the reality of the role.
A machine learning engineer doesn’t just build models. They maintain systems, debug pipelines, coordinate across teams, and ensure that what works today still works tomorrow.
The modeling is only part of the job. The rest is engineering.
Day in the Life: AI Engineer
You start your day not by checking models, but by checking behavior.
One of your AI systems, a retrieval-based assistant, is failing a specific type of question. It’s hallucinating pricing details. Not completely wrong, but inconsistent enough to break trust. You trace it back to the source. The retriever is pulling conflicting documents. Two versions of the same pricing page were embedded, and no one cleaned them up.
You fix the ingestion logic. Not the model. The system around it.
Later, you’re in a product meeting. The feedback sounds simple. “Make it sound less robotic.” But you know that tone isn’t the real issue. The system struggles when it’s uncertain. Instead of masking it with better phrasing, you suggest a fallback. If confidence is low, escalate to a human. This is less about AI and more about designing reliable experiences.
Back at your desk, you’re experimenting again, but not with models. With prompts. You’re trying to make the system output structured JSON so another service can consume it. You test multiple prompt versions, run them across dozens of cases, and score the outputs. Small wording changes lead to measurable differences.
Later, you improve the retrieval pipeline itself. You add a reranking step, run evaluation metrics, and see a clear jump in answer quality. This is what progress looks like here. Not training a new model, but improving how the system uses one.
By the end of the day, you ship a new version. You don’t just deploy it blindly. You log it, track it, and set up an A/B test to compare performance over the next few days.
That’s the reality of the role.
An AI engineer doesn’t just “use models.” They design systems, evaluate behavior, and shape how intelligence interacts with users.
The job sits between engineering and product.
And the difference between a good AI engineer and someone just prompting models is simple:
One builds systems that work.
The other hopes the prompt works.
Skills gap self-assessment
Before choosing a track, be honest about where you are today. Go through each area and rate yourself: strong, working knowledge, or gap.
· Programming Can you write clean Python beyond tutorials? Do you understand when to use a class vs a function? Can you read someone else’s code and debug it without help? If Python still feels shaky, both tracks will be harder than they need to be. Fix this first.
· Statistics & math Do you understand what a probability distribution means intuitively? Can you explain why R² isn’t always the right metric? Do you know what overfitting looks like and why it happens? ML Engineering requires deeper math fluency. AI Engineering needs enough to evaluate models critically — you don’t need to derive backpropagation, but you need to understand what training loss means.
· Software engineering habits Do you use Git regularly? Do you write code that other people could read in six months? Have you built anything end-to-end — even a small web app? AI Engineering requires stronger software engineering instincts than most people expect. You’re building production systems, not research prototypes.
· Domain familiarity Have you worked with real data? Have you trained any model at all, even logistic regression? Have you called an API and built something with the output? For ML Engineering, the gap here is substantial if you’re starting from zero. For AI Engineering, someone with strong software skills can close this gap faster.
If your math is weak, AI Engineering is the more accessible entry point. If your software engineering is weak, spend time there before either track — it’s the foundation everything else runs on.
Choosing your primary track
After going through the comparisons above, most people find that one track clearly resonates more than the other. But if you’re still on the fence, here are the questions that tend to break the tie.
Choose ML Engineering if:
You’re drawn to understanding how models work at a mathematical level, not just using them
You find data pipelines, feature engineering, and systems architecture interesting
You want a role with a longer established track record and more clearly defined career ladders
You’re interested in eventually moving toward research
Choose AI Engineering if:
You want to build products and see them used, more than you want to understand model internals
You have a strong software background and want to apply it to AI without going deep into math
You want to get to your first AI-related role as quickly as possible
You’re excited by the pace of the current LLM ecosystem
One important note: these tracks converge over time. Senior AI Engineers need to understand fine-tuning and model behavior deeply. Senior ML Engineers are increasingly expected to work with LLMs. Choosing a primary track doesn’t close the other door — it just sets your starting point.
Pick the one that gets you excited to study at 10pm. That’s the right answer.
Building a sustainable learning system
Most people start a technical roadmap with a lot of energy and stall out by week four. The content isn’t the problem; the system is.
· Protect a consistent block of time, not a consistent number of hours. “I’ll study 2 hours every day” breaks the moment life gets busy. “I study from 7–9am Tuesday, Wednesday, Friday” survives it. Consistency of schedule beats ambition of volume.
· Build in public from day one. Not because it’s good for your brand (though it is), but because the commitment of sharing work externally forces you to actually finish things. A notebook that lives on your laptop is a draft. A GitHub repo with a README is a project.
· Learn by building, not by watching. Tutorials create the illusion of learning. The actual learning happens the first time you try to reproduce something without the tutorial open. For every hour of course content, spend at least an hour building something adjacent to it — slightly different dataset, slightly different problem.
· Track what you’ve built, not how many hours you’ve studied. Hours are inputs. Projects are outputs. At the end of each month, ask: what can I show for this month that I couldn’t show last month? If the answer is nothing, the learning system isn’t working.
· Don’t over-plan the back half of the roadmap. Get clear on the next four to six weeks. The rest can stay fuzzy. Over-planning creates the feeling of productivity without any real work getting done.
The people who complete a learning roadmap like this aren’t the most talented or the most knowledgeable at the start. They’re the ones who built the smallest, most defensible learning habit and protected it.
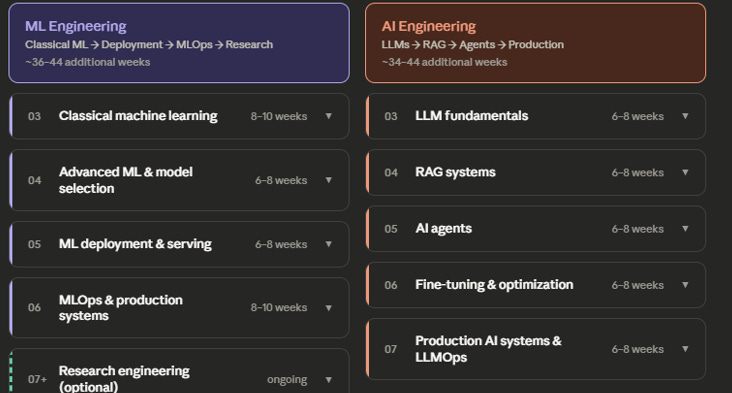
ML Engineer Vs. AI Engineer Roadmap: Shared Path for Both
As mentioned earlier, both ML engineer and AI engineer share similarities, but it’s not very simple. I’ll share these similarities in the next section before we get technical.
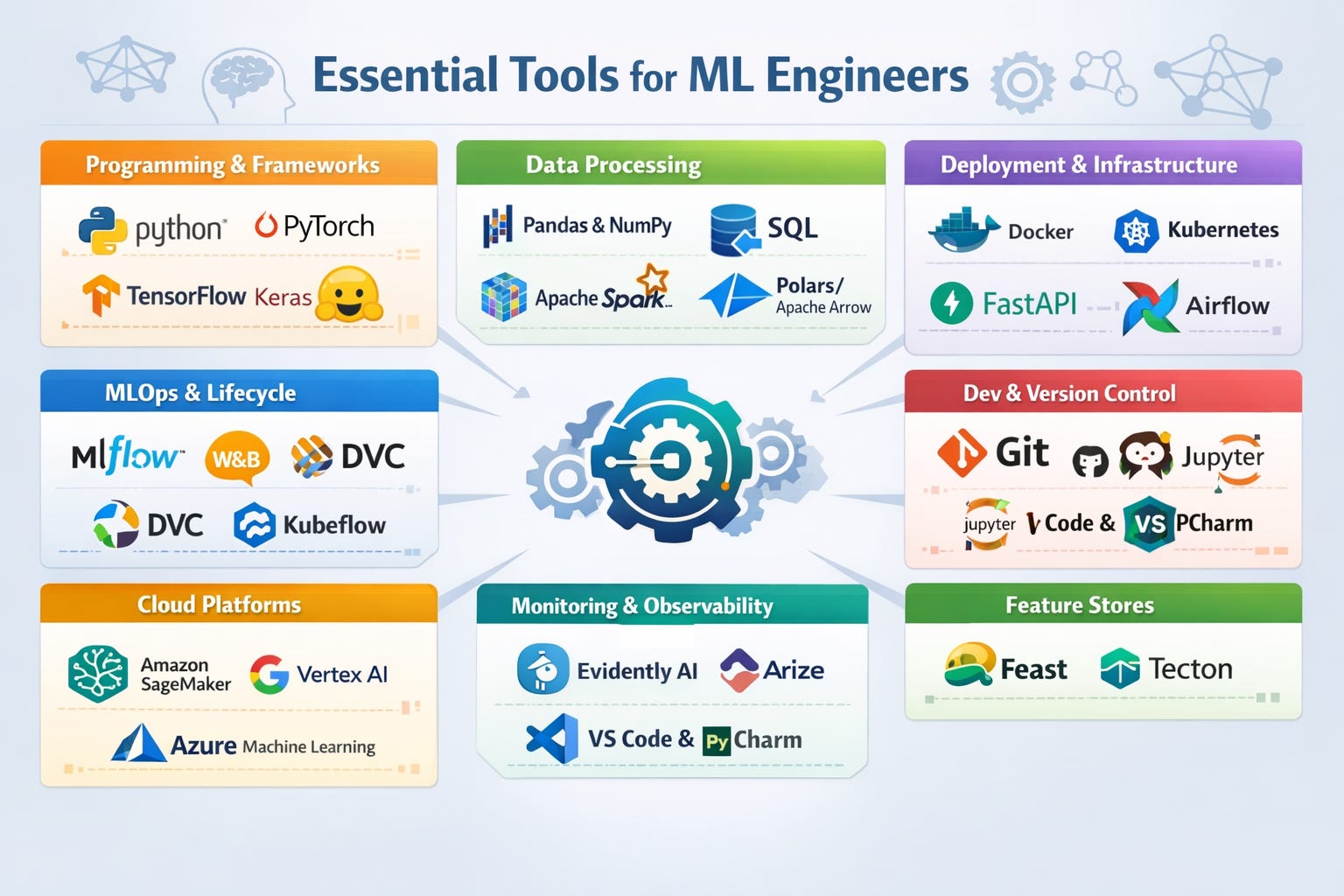
Python & programming foundations
Before you touch a single ML algorithm or LLM API, you need Python to feel natural. Not perfect — natural. The goal at this stage isn’t to become a software engineer. It’s to get comfortable enough that the language stops being the bottleneck when you’re trying to learn something else.
Python syntax, loops & functions
Start with the basics and don’t rush them. Variables, conditionals, loops, and functions are the vocabulary everything else is written in. Pay particular attention to functions — understanding how to write clean, reusable functions early will save you enormous pain when your projects grow. If you find yourself copy-pasting the same five lines of code, that’s a function waiting to be written.
Data structures
Lists, dictionaries, and sets aren’t just trivia — they’re how you’ll represent and manipulate data throughout your entire career. Know when to use each one. A list is ordered and allows duplicates. A dictionary maps keys to values and gives you fast lookups. A set handles uniqueness efficiently. Most data preprocessing tasks are just combinations of these three.
NumPy for numerical computing
NumPy is the foundation everything else in the scientific Python ecosystem sits on. The most important concept to internalize here is vectorization — the idea that you can apply an operation to an entire array at once rather than looping over each element. This is both faster and more readable. Get comfortable with array shapes, broadcasting, and indexing before moving on.
Pandas for data manipulation
Pandas is where you’ll spend most of your time in the early stages of any project. DataFrames, filtering, groupby, merging, handling missing values, reshaping — these operations will become muscle memory. The best way to learn Pandas is to pick a messy real-world dataset and actually clean it. No tutorial dataset is messy enough to teach you what you need to know.
Matplotlib & Seaborn for EDA
Exploratory data analysis is the first thing you do on any new dataset, and visualization is how you do it. You need to be able to plot distributions, spot outliers, check correlations, and communicate findings visually. Matplotlib gives you the control. Seaborn gives you the speed. Learn both — you’ll use them differently depending on whether you’re exploring or presenting.
Git & version control
Git is non-negotiable. Every project you build should live in a Git repository from day one. Learn the core workflow: init, add, commit, push, branch, merge. You don’t need to master rebasing or advanced branching strategies yet. You need to build the habit of committing regularly with meaningful messages. Your GitHub profile is your portfolio — start treating it that way now.
Virtual environments & packaging
This is the topic most beginner tutorials skip and everyone eventually pays for. Dependency conflicts between projects are a real problem. Learn to create and manage virtual environments with venv or conda, and understand what a requirements.txt file is for. This is basic professional hygiene in Python development.
Important: SQL fundamentals
Data lives in databases, and SQL is how you get it out. Most ML engineering roles expect you to be able to write queries without help — SELECT, WHERE, GROUP BY, JOIN, subqueries. You don’t need to be a database administrator. You need to be able to pull the data you want without asking someone else to do it for you.
Math for machine learning
You do not need a mathematics degree to become an ML or AI Engineer. But you do need enough mathematical intuition to understand what your models are actually doing — because without it, you’re debugging blindly. The emphasis here is on intuition over computation. You should be able to reason through these ideas, not necessarily derive them from first principles.
Linear algebra — vectors & matrices
Almost everything in machine learning is a matrix operation. Data is stored as matrices. Model parameters are stored as vectors. Transformations happen through matrix multiplication. The key concepts to internalize: what a vector represents geometrically, what matrix multiplication actually does (it’s a transformation, not just arithmetic), and what it means for a matrix to be invertible. Once you see data as vectors in high-dimensional space, a lot of ML concepts that seemed abstract will click into place.
Calculus — derivatives & the chain rule
Neural networks learn through a process called backpropagation, which is built entirely on the chain rule from calculus. You don’t need to be able to derive it by hand in an interview, but you need to understand it conceptually: a derivative tells you how much a function’s output changes when you nudge the input. In ML, you’re using derivatives to figure out which direction to adjust your model’s parameters to reduce error. The chain rule lets you do this across many stacked layers.
Probability & Bayes’ theorem
Machine learning models don’t output certainties — they output probabilities. Understanding probability distributions, conditional probability, and Bayes’ theorem is what lets you reason about model outputs correctly. Bayes’ theorem in particular is foundational: it describes how to update your belief about something given new evidence. This underpins everything from Naive Bayes classifiers to how Bayesian optimization works in hyperparameter tuning.
Statistics & distributions
Know the major probability distributions — normal, binomial, Poisson — and what kinds of real-world phenomena they model. Understand mean, variance, and standard deviation not as formulas but as descriptions of shape. Know the difference between a sample and a population. Understand what a p-value actually tells you (and what it doesn’t). A lot of feature engineering decisions and model evaluation choices come down to statistical reasoning.
Hypothesis testing basics
You’ll use hypothesis testing more than you expect — when deciding whether a new model is actually better than the old one, when evaluating A/B tests on deployed models, when determining whether a feature adds real signal or just noise. The core idea: define a null hypothesis, measure whether your data is surprising under that assumption, and make a decision. Understand Type I and Type II errors — false positives and false negatives exist in statistics just as they do in your confusion matrix.
Intuition over computation
The trap with this section is spending months grinding calculus problems when you should be building models. You’re not preparing for a mathematics exam. You’re preparing to understand papers, debug unexpected model behavior, and make informed architectural decisions. Use visual resources heavily — 3Blue1Brown’s Essence of Linear Algebra and Essence of Calculus series are the best time investment you can make here. Seeing these concepts animated is worth more than any textbook for the purpose of building intuition.
ML Engineer Roadmap: Classical machine learning
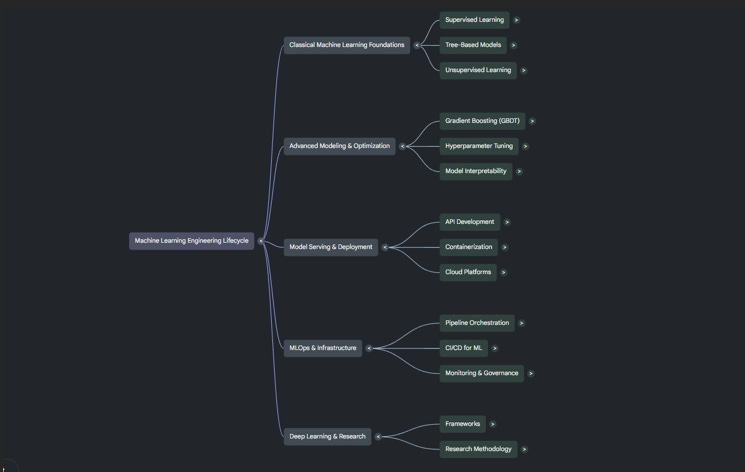
This is where the fundamentals live. Before you touch deployment infrastructure or production pipelines, you need to deeply understand what a machine learning model actually does — how it learns from data, where it fails, and why. Everything in this section will be referenced for the rest of your career. Don’t rush it.
Supervised learning — regression & classification
Supervised learning is the core of classical ML. You have labeled data — inputs paired with known outputs — and your job is to train a model that learns the relationship between them well enough to generalize to new inputs it’s never seen.
Regression predicts a continuous value. Classification predicts a category. The math is different, the metrics are different, and the failure modes are different, but the underlying logic is the same: you’re trying to find a function that maps inputs to outputs with minimum error. Understand both deeply before moving to more complex algorithms.
Linear & logistic regression from scratch
These two algorithms are the best starting point in all of machine learning — not because you’ll use them constantly in production, but because implementing them from scratch forces you to understand the mechanics everything else is built on.
Linear regression fits a line (or hyperplane) through data by minimizing the sum of squared errors. Logistic regression extends this to classification by squashing outputs through a sigmoid function to produce probabilities. Build both without scikit-learn first. Once you’ve written the gradient descent update loop by hand, you’ll understand what every other model is doing under the hood.
Decision trees & random forests
Decision trees are intuitive — they make predictions by asking a series of yes/no questions about your features. The problem is they overfit easily. A tree that perfectly classifies training data by memorizing every example is useless on new data.
Random forests solve this by building many trees, each trained on a random subset of data and features, and averaging their predictions. This ensemble approach dramatically reduces variance without much increase in bias. Understanding the bias-variance tradeoff in the context of trees is one of the most important conceptual milestones in this phase.
Unsupervised learning — clustering & PCA
Not all data comes with labels. Unsupervised learning finds structure in unlabeled data. K-means clustering groups data points by similarity. PCA (Principal Component Analysis) reduces dimensionality by finding the directions in your data that explain the most variance.
These techniques show up constantly in practice — for customer segmentation, anomaly detection, data compression, and as preprocessing steps before supervised learning. PCA in particular is worth understanding geometrically, not just mechanically. You’re rotating your data into a new coordinate system where the axes are ordered by how much variation they capture.
Feature engineering & preprocessing
In practice, the quality of your features matters more than the sophistication of your model. Feature engineering is the process of transforming raw data into representations that make it easier for a model to learn.
This includes handling missing values, encoding categorical variables, scaling numerical features, creating interaction terms, and extracting meaningful signals from raw data like dates, text, or IDs. There’s no formula for good feature engineering — it requires domain understanding and experimentation. It’s also where experienced ML engineers create the most value over beginners.
scikit-learn end-to-end workflows
scikit-learn is your primary toolkit for classical ML. Its consistent API — fit, transform, predict — works across virtually every algorithm, making it fast to experiment. More importantly, its Pipeline object lets you chain preprocessing steps and a model together into a single object that can be trained, evaluated, and deployed as a unit.
Learn Pipelines early. They prevent data leakage, make your code reproducible, and are the professional standard for production ML work.
Evaluation metrics — AUC, F1, RMSE
Accuracy is almost never the right metric. For imbalanced classification problems, a model that predicts the majority class every time can have 95% accuracy and be completely useless. Know your metrics and when to use them.
AUC-ROC measures how well a classifier separates classes across all decision thresholds. F1 score balances precision and recall — useful when false positives and false negatives carry different costs. RMSE penalizes large errors more heavily than MAE for regression tasks. The right metric depends on the business problem, and being able to argue for your metric choice is a core ML engineering skill.
Bias-variance tradeoff
This is the central tension in machine learning. A model that’s too simple — high bias — underfits: it misses the real patterns in the data. A model that’s too complex — high variance — overfits: it memorizes the training data and fails on anything new.
Your entire job as an ML engineer is navigating this tradeoff. Regularization, cross-validation, early stopping, ensemble methods — all of these are tools for managing bias and variance. Understand it conceptually before you reach for any of them.
Advanced ML & model selection
Once you have the fundamentals solid, this phase sharpens your ability to actually win on real-world problems. Classical algorithms with default settings rarely perform at the level production systems require. Here you learn how to push model performance — systematically, not by guessing.
XGBoost, LightGBM & CatBoost
Gradient boosting algorithms dominate structured/tabular data competitions and production ML systems alike. The core idea: instead of building many independent trees like random forests, you build trees sequentially, where each new tree corrects the errors of the previous ones.
XGBoost popularized this approach and is still widely used. LightGBM is faster and more memory-efficient, making it preferred for large datasets. CatBoost handles categorical features natively without preprocessing. Know all three, understand their tradeoffs, and develop a default preference — most experienced practitioners start with LightGBM and adjust from there.
Cross-validation strategies
Training accuracy is a lie. The only accuracy that matters is on data your model has never seen. Cross-validation gives you a reliable estimate of this by training and evaluating your model multiple times on different splits of your data.
Standard k-fold works well for most problems. For time-series data you need time-aware splits that respect temporal order — using future data to predict the past is a form of leakage. For highly imbalanced datasets, stratified k-fold ensures each fold preserves the class ratio. Choosing the wrong validation strategy is one of the most common sources of inflated performance estimates in ML.
Hyperparameter tuning with Optuna
Every algorithm has hyperparameters — settings you choose before training that control the learning process. The learning rate, tree depth, regularization strength, number of estimators. Getting these right matters significantly for final performance.
Optuna is the modern standard for this. It uses Bayesian optimization to search the hyperparameter space efficiently — rather than exhaustively trying every combination (grid search) or sampling randomly, it builds a probabilistic model of which hyperparameters are likely to perform well and focuses search there. The result is faster convergence to good configurations with fewer trials.
Handling class imbalance
Real-world classification problems are almost never balanced. Fraud detection might have 0.1% positive cases. Medical diagnosis might have 5% positive. Default algorithm behavior on these datasets produces models that effectively ignore the minority class.
SMOTE (Synthetic Minority Oversampling Technique) generates synthetic samples of the minority class to rebalance training data. But oversampling isn’t always the right answer — sometimes adjusting class weights in the model, or choosing a threshold other than 0.5 for classification decisions, is more appropriate. Understand the tradeoffs. The choice depends on whether false positives or false negatives are more costly in your specific problem.
Stacking & blending ensembles
Individual models have blind spots. Ensembling — combining predictions from multiple models — reduces these blind spots by exploiting the fact that different algorithms fail in different ways.
Stacking trains a meta-model on the out-of-fold predictions of several base models. Blending is a simpler variant using a held-out validation set. The performance gains from good ensembling can be significant, which is why Kaggle competition leaderboards are almost always topped by ensemble solutions. More importantly for your career, understanding ensembles teaches you to think about model error systematically rather than looking for a single perfect algorithm.
Interpretability — SHAP & LIME
Telling someone their loan was denied by a gradient boosting model is not enough — regulators, product teams, and end users increasingly require explanations. Even when they don’t, you need interpretability for your own debugging.
SHAP (SHapley Additive exPlanations) assigns each feature a contribution to a specific prediction based on game theory. It’s consistent, model-agnostic, and produces both global feature importance and local per-prediction explanations. LIME approximates model behavior locally around a specific prediction with a simpler interpretable model. Both tools belong in your default workflow, not just when someone asks for an explanation.
ML deployment & serving
Building a model that works in a notebook is a solved problem. Getting that model to serve predictions reliably to real users, under real traffic, with real latency constraints — that’s where most of the engineering work actually lives.
FastAPI for model serving
FastAPI is the standard for wrapping ML models in a REST API. It’s fast, modern, and generates automatic documentation. The pattern is straightforward: load your trained model at startup, expose a prediction endpoint that accepts input, runs it through your preprocessing pipeline, calls model.predict(), and returns the result.
The subtleties come in the details: how you handle input validation, how you manage model loading time, how you version your endpoint, and how you handle errors gracefully when inputs don’t match expectations. Learn these patterns before you worry about scale.
Docker & containerization
A model that works on your laptop needs to work identically on a server, on a colleague’s machine, and in a cloud environment. Docker solves this by packaging your code, its dependencies, and the runtime environment into a single container that runs consistently everywhere.
Write a clean Dockerfile for your model service. Understand the difference between an image and a container. Know how to optimize image size — large images slow down deployments. Learn docker-compose for running multi-service setups locally. Containerization is not optional in production ML — it’s table stakes.
Cloud platforms — AWS, GCP & Azure
You don’t need to master all three, but you need working fluency in at least one. The core services you’ll use most as an ML engineer: object storage (S3, GCS, Azure Blob) for storing data and model artifacts, compute instances for training jobs, container registries for storing Docker images, and managed deployment services (SageMaker, Vertex AI, Azure ML) for serving models at scale.
Start with AWS if you’re undecided — it has the largest market share and the most job postings referencing it. The concepts transfer directly across providers.
REST APIs for ML models
Understand how REST APIs work at the HTTP level — not just how to use them. Know the difference between GET and POST requests, how to structure request and response bodies as JSON, how authentication works with API keys and tokens, and how to handle errors with appropriate status codes.
When you expose a model as an API, you’re making a contract with every downstream system that uses it. Changes to your input schema or output format are breaking changes. Versioning your API from the start prevents the kind of coordination nightmares that plague production ML teams.
Model serialization — pickle, ONNX & joblib
A trained model needs to be saved to disk and loaded back for serving. Pickle is the simplest approach but has limitations: it’s Python-specific and can be fragile across library versions. Joblib is preferred for scikit-learn models because it handles large numpy arrays more efficiently.
ONNX is the more robust option for production: it’s a framework-agnostic format that lets you train in scikit-learn or PyTorch and deploy in a completely different runtime. Understanding serialization formats becomes important when your deployment infrastructure is separate from your training infrastructure — which it almost always is in production.
Batch vs real-time inference
Not all predictions need to be made instantly. Real-time inference returns predictions in milliseconds in response to individual requests — required for fraud detection, recommendation systems, anything user-facing. Batch inference runs predictions on large datasets periodically, writing results to a database for later lookup — appropriate for churn scoring, lead scoring, or any use case where staleness of a few hours is acceptable.
Batch inference is dramatically cheaper and simpler to operate. Real-time inference requires low-latency serving infrastructure, careful optimization, and more robust monitoring. Choosing the wrong pattern for your use case is a common and expensive mistake.
MLOps & production systems
This is where ML Engineering diverges most sharply from data science. MLOps is the discipline of running machine learning systems reliably at scale over time. A model isn’t done when it’s deployed — it needs to be monitored, retrained, versioned, and maintained, often for years.
ML pipelines — ZenML, Prefect & Airflow
A pipeline is a directed sequence of steps — data ingestion, preprocessing, feature engineering, training, evaluation — that can be run automatically, reproducibly, and on a schedule. Without pipelines, retraining a model means manually re-running a series of notebooks in the right order. That doesn’t scale.
Airflow is the most widely deployed option and worth knowing for its market presence. Prefect is more modern and easier to work with for ML workflows. ZenML is purpose-built for ML pipelines and integrates with experiment tracking tools natively. The specific tool matters less than the concept: your entire training workflow should be codified as a pipeline that can be triggered with a single command.
Experiment tracking — MLflow & Weights & Biases
Every training run is an experiment. You change a hyperparameter, add a feature, try a different algorithm. Without tracking, you lose the ability to reproduce past results or understand why one model performs better than another.
MLflow tracks parameters, metrics, and model artifacts for each run and provides a UI to compare them. Weights & Biases (W&B) does the same with a stronger emphasis on visualization and collaboration. Use one from the start of every project — retrofitting experiment tracking onto an existing codebase is painful. The habit of logging every experiment is worth building early.
Model registry & versioning
A model registry is a central store of trained model versions with metadata: who trained it, what data it was trained on, what metrics it achieved, and which version is currently serving production traffic. MLflow has one built in. SageMaker, Vertex AI, and Azure ML all have managed registries.
Model versioning solves a specific problem: when something goes wrong in production, you need to be able to roll back to a previous version instantly. Without a registry, this is manual and error-prone. With one, a rollback is a one-line command.
Data drift & model monitoring
Models go stale. The world changes — customer behavior shifts, fraud patterns evolve, market conditions move — and a model trained on last year’s data becomes increasingly wrong. Data drift is when the statistical distribution of incoming data diverges from the training data. Concept drift is when the underlying relationship between features and the target changes.
Neither is detectable without monitoring. You need to track input feature distributions over time, compare prediction distributions against baseline, and monitor outcome metrics where ground truth is available with a delay. When drift is detected, you need a retrain trigger — either automated or alerting a human to make that call.
CI/CD for ML with GitHub Actions
Continuous integration and continuous deployment, applied to ML. When you push a change to your training code, a CI/CD pipeline should automatically run your test suite, validate data schemas, train or fine-tune on a sample, evaluate against a baseline, and only promote the new model to production if it passes.
This sounds like overhead until your team has shipped a model that degraded production metrics because nobody caught a preprocessing bug. GitHub Actions is the most accessible entry point — you can define your entire ML CI/CD pipeline in a YAML file alongside your code.
Feature stores
A feature store is a centralized system for managing the features used to train and serve models. It solves two problems simultaneously: training-serving skew (when features are computed differently at training time vs serving time) and feature reuse (when multiple models need the same features and are computing them redundantly).
Feast is the most widely used open-source option. Tecton and Hopsworks are managed alternatives. Feature stores are most valuable at organizational scale — when multiple teams are building models on the same underlying data. Understanding the concept is important even if your first few projects don’t require one.
Research engineering (optional)
This track extension is for those who want to go beyond applying existing algorithms and start contributing to the development of new ones. It’s not required for most ML engineering roles, but it opens different doors — research positions at AI labs, opportunities to work on frontier model development, and the ability to read and implement ideas from papers before they become standard tools.
Deep learning fundamentals with PyTorch
PyTorch is the dominant framework for deep learning research and increasingly for production systems as well. The core concepts: tensors, autograd (automatic differentiation), neural network layers, loss functions, and optimizers.
Build simple networks from scratch before using high-level abstractions. Train a multilayer perceptron on tabular data. Train a CNN on images. Implement a basic RNN. Each of these exercises builds a different piece of intuition about how gradient-based learning actually works. Once you understand what’s happening inside a training loop at the tensor level, the abstractions stop being magic.
Reading & understanding ML papers
Research papers are the primary medium through which new ideas in ML are communicated. Getting comfortable reading them is a skill that takes deliberate practice.
Start with papers that have become foundational — the original XGBoost paper, the Attention Is All You Need transformer paper, the BERT paper. Read the abstract and conclusion first to understand the claim. Then read the experiments section to understand how the claim was evaluated. Read the method section last, with the context of what it’s trying to prove. Don’t expect to understand everything on the first pass. The goal is to develop intuition for how ML research is structured and argued.
Paper reproduction projects
Reading a paper is passive. Reproducing it is active. Pick a paper with a clear, bounded contribution — a specific architecture improvement, a training technique, an augmentation method — and implement it from scratch using only the paper and any referenced prior work.
You will find ambiguities the paper doesn’t address. You will hit implementation details that matter more than the paper suggests. You will probably not exactly replicate the reported numbers on the first attempt. All of this is the point. Paper reproduction is how research engineers develop the instinct for what details actually matter in ML implementations.
Custom architecture design
Once you can implement existing architectures from papers, the next step is modifying them. Change the attention mechanism. Add a new regularization term. Combine components from two different papers. This is how most real ML research actually works — not inventing entirely new paradigms, but systematically varying existing components and measuring the effect.
Ablation studies are your primary tool here: hold everything constant, change one thing, measure the difference. Rigorous ablations are what separate engineering contributions from guesswork.
Open-source contributions
Contributing to open-source ML projects is the fastest way to develop the kind of collaborative engineering skills that research roles require — reading unfamiliar codebases, understanding project conventions, writing code that meets other people’s standards, and navigating code review.
Start small. Fix a documentation issue. Add a test case. Implement a minor feature requested in the issues. The mechanics of contributing — forking, branching, PRs, reviews — are as important to learn as the technical content. Your contribution history is also a credible signal in applications to research-oriented roles, where demonstrating engagement with the broader ML community matters.
ML Engineering portfolio projects
Your ML engineering portfolio should demonstrate more than models. It should show how you design, build, and ship real systems. Strong projects highlight data pipelines, decision logic, deployment, and monitoring. The goal is to prove you can solve real business problems, not just train algorithms in isolation.
1. Customer churn prediction system
Stack: Python, Pandas, scikit-learn, XGBoost, FastAPI, Docker, MLflow
A telecom or SaaS company loses revenue every time a customer cancels. Your job is to predict which customers are likely to churn before they do, so the business can intervene.
Start with a public dataset — the IBM Telco churn dataset is ideal. Do thorough EDA to understand which features correlate with churn: contract type, tenure, monthly charges, support tickets. Engineer new features like charge-per-month ratio or days since last interaction. Train a baseline logistic regression first, then graduate to XGBoost. Tune with Optuna. Use SHAP to explain which features are driving predictions at both a global and per-customer level.
Wrap the final model in a FastAPI endpoint that accepts customer data as JSON and returns a churn probability and the top three contributing factors. Containerize with Docker. Track every experiment in MLflow. The SHAP explanations are what elevate this beyond a standard Kaggle submission — they simulate the kind of explainability a real business would demand before acting on model predictions.
2. House price regression with full preprocessing pipeline
Stack: Python, Pandas, scikit-learn, Optuna, Streamlit, joblib
Regression is foundational and the Ames Housing dataset is the best real-world regression dataset available for learning — 79 features, substantial missing data, mixed types, and enough complexity to require real engineering.
The core challenge here isn’t the model — it’s the preprocessing pipeline. Build a robust scikit-learn Pipeline that handles numerical imputation, categorical encoding, feature scaling, and optional polynomial feature generation as a single serializable object. This forces you to confront every data quality issue methodically rather than patching them ad hoc in a notebook.
Train multiple regressors — Ridge, Random Forest, gradient boosting — and build a simple stacking ensemble as the final model. Expose it through a Streamlit app where users can input house characteristics and get a predicted price with a confidence interval. The emphasis on the Pipeline object is what makes this project stand out to interviewers — it demonstrates that you understand production-grade code, not just model accuracy.
3. Credit card fraud detection with class imbalance handling
Stack: Python, scikit-learn, imbalanced-learn, LightGBM, Matplotlib, FastAPI
Fraud detection is a canonical class imbalance problem — legitimate transactions outnumber fraudulent ones by several hundred to one. The dataset most commonly used is the Kaggle Credit Card Fraud dataset, which reflects this ratio accurately.
The interesting work here is in the evaluation and resampling strategy. Accuracy is meaningless — a model that predicts “not fraud” every time is 99.8% accurate and completely useless. Use precision-recall curves and AUC-PR as your primary metrics. Experiment systematically with three approaches: SMOTE oversampling, class weight adjustment in LightGBM, and threshold tuning on the decision boundary. Document which approach performs best and why — this analytical rigor is what interviewers are looking for.
Build a cost-aware evaluation: assign a dollar value to false negatives (missed fraud) and false positives (wrongly blocked transactions) and compute the financial cost of each model variant. This frames the technical problem in business terms, which is a skill that distinguishes strong ML engineers from those who only think in metrics.
4. End-to-end NLP text classifier with deployment
Stack: Python, scikit-learn, sentence-transformers, FastAPI, Docker, Render or Railway
Text classification is one of the most common real-world ML tasks and a strong portfolio signal. Use a multi-class classification problem — customer support ticket categorization, news topic classification, or Stack Overflow question tagging all work well.
The key decision point in this project is the embedding strategy. Start with TF-IDF + logistic regression as a strong baseline — you’ll be surprised how competitive this is. Then move to sentence-transformers to generate dense semantic embeddings and compare. The performance difference illustrates exactly why contextual embeddings matter and is a natural talking point in interviews.
Build an evaluation suite that goes beyond accuracy: a confusion matrix that highlights which categories the model confuses most, error analysis on the worst-performing examples, and latency benchmarking of TF-IDF vs transformer embeddings under load. Deploy the final model to a free cloud tier (Render or Railway work well) so you have a live public endpoint to include in your portfolio. A deployed model beats a notebook every single time.
5. Time-series forecasting pipeline
Stack: Python, Pandas, Prophet, LightGBM, scikit-learn, Streamlit, MLflow
Time-series problems appear constantly in industry — demand forecasting, energy consumption, stock indicators, website traffic — and they require a different mindset than standard supervised learning because the temporal order of data is itself a feature.
Use a public dataset with a meaningful forecasting target — the M5 competition retail sales data or hourly energy consumption data both work well. The critical learning in this project is around correct train/test splitting: you cannot use future data to predict the past, which means no random shuffling, no standard k-fold, only time-ordered splits.
Build two model types side by side: a statistical baseline with Facebook Prophet and a gradient boosting model (LightGBM) with hand-crafted lag features and rolling window aggregates. The lag features — sales from 7 days ago, 28 days ago, rolling 4-week average — are the engineering work that makes the LightGBM model competitive. Compare both on the same held-out test period and document the tradeoffs. Wrap the pipeline in Streamlit with an interactive date range selector for the forecast horizon.
6. ML pipeline with automated retraining on AWS
Stack: Python, scikit-learn, MLflow, Prefect, AWS S3, AWS EC2, Docker, GitHub Actions
This project is less about model performance and more about demonstrating MLOps maturity — which is exactly what separates candidates who can build models from candidates who can run ML in production.
Use any reasonably interesting classification problem as the underlying model. The project is the infrastructure around it. Build a Prefect pipeline that pulls data from S3, runs preprocessing, trains the model, logs metrics to MLflow, and promotes the new model to the registry only if it beats the current production model on a held-out validation set. Set up GitHub Actions to trigger this pipeline when new data lands in the S3 bucket.
Add a simple monitoring script that runs on a schedule, computes feature distribution statistics on recent inference data, and writes a drift report. When drift is detected above a threshold, it triggers a Slack notification. This is the kind of end-to-end automation that takes a project from “interesting model” to “production ML system” — and that distinction is exactly what MLOps roles are hiring for.
7. Recommendation system
Stack: Python, NumPy, scikit-learn, Surprise or Implicit, FastAPI, Redis, Docker
Recommendation systems are one of the highest-impact ML applications in industry and appear in almost every consumer product at scale. Understanding them demonstrates that you can think about ML problems from the perspective of user behavior data, not just feature tables.
Use the MovieLens dataset, which is realistic, well-documented, and large enough to make naive approaches slow. Build three systems in sequence: a popularity baseline (recommend what’s globally popular), a collaborative filtering model using matrix factorization, and a content-based model using movie metadata embeddings. Measure each on precision@k and recall@k on a held-out test set. The progression from baseline to collaborative to content-based tells a clear story about tradeoffs between approaches.
The engineering challenge worth adding: serve recommendations with sub-100ms latency by precomputing top-N recommendations for each user at training time and caching them in Redis. This simulates the real production pattern for recommendation systems — you rarely compute recommendations in real time at inference; you precompute and cache. Documenting this decision in your README is the kind of systems thinking that interviewers remember.
8. Tabular AutoML benchmarking project
Stack: Python, scikit-learn, XGBoost, LightGBM, CatBoost, Optuna, FLAML or AutoGluon, Pandas
This project is unconventional and that’s its strength. Instead of building one model on one dataset, you build a rigorous benchmarking framework that evaluates multiple algorithms and AutoML tools across multiple datasets — and document your findings.
Pick five to eight public datasets with varying characteristics: high-cardinality categoricals, significant class imbalance, small data, large data, high dimensionality. For each dataset, run your manual pipeline — feature engineering, hyperparameter tuning with Optuna, ensemble — against an AutoML baseline from FLAML or AutoGluon. Track every experiment in MLflow. Write a detailed analysis of where AutoML matches or beats manual approaches and where it falls short.
The deliverable is a written report alongside the code. This project demonstrates analytical rigor, breadth of ML knowledge, and the ability to draw conclusions from experiments — which are the core skills of a senior ML engineer, not just the ability to tune a single model.
9. Anomaly detection system for IoT sensor data
Stack: Python, scikit-learn, PyOD, Pandas, FastAPI, Streamlit, Docker
Anomaly detection is a genuinely hard unsupervised problem — you’re trying to find unusual patterns without labeled examples of what “unusual” looks like. It appears in manufacturing, cybersecurity, infrastructure monitoring, and healthcare.
Use a public sensor dataset — the NASA Turbofan engine degradation dataset or the Numenta Anomaly Benchmark work well. Implement three approaches: statistical (z-score and IQR-based), classical unsupervised (Isolation Forest, Local Outlier Factor), and a reconstruction-based method (training an autoencoder in PyTorch and flagging high reconstruction error as anomalous). Compare them using the limited ground truth labels that these datasets provide.
The Streamlit dashboard is the deliverable that makes this portfolio-worthy: upload a CSV of sensor readings, run all three detectors, and visualize flagged anomalies on a time-series plot with confidence scores. Color-code anomalies by detector agreement — points flagged by all three methods are displayed differently from those flagged by only one. This multi-detector consensus pattern is a real production pattern that shows you’ve thought beyond accuracy to operational reliability.
10. Full MLOps project with model monitoring and drift detection
Stack: Python, scikit-learn, Evidently AI, MLflow, Prefect, FastAPI, Docker, PostgreSQL, Grafana
This is the capstone-level project — the one that demonstrates the full picture of what production ML actually looks like. It combines model development, deployment, monitoring, and automated response into a single system.
Train a model on a dataset where you can simulate real-world deployment — credit scoring, insurance pricing, or any tabular problem where you can deliberately introduce drift in the inference data. Build the full serving stack: a FastAPI endpoint logs every prediction — inputs, outputs, timestamps, and model version — to a PostgreSQL database.
Run Evidently AI on a schedule to compute drift reports comparing the current inference data distribution to the training distribution. Store these reports and surface them through a Grafana dashboard. When drift exceeds a configurable threshold, a Prefect pipeline triggers automatically: it pulls recent labeled data (simulated in your project), retrains the model, evaluates it against the current production model, and conditionally promotes it to the registry.
Write a detailed README that documents every architectural decision and the reasoning behind it. This project won’t be the most impressive model you’ve built — but it’s the most impressive system, and the distinction matters enormously for MLOps and senior ML engineering roles.
AI Engineering: LLMs Fundamentals
Large language models are the most consequential technology shift in software engineering since the cloud. But most people using them don’t understand what they actually are — and that gap shows up immediately when something breaks in production. This section closes that gap before you build anything.
How transformers & attention work
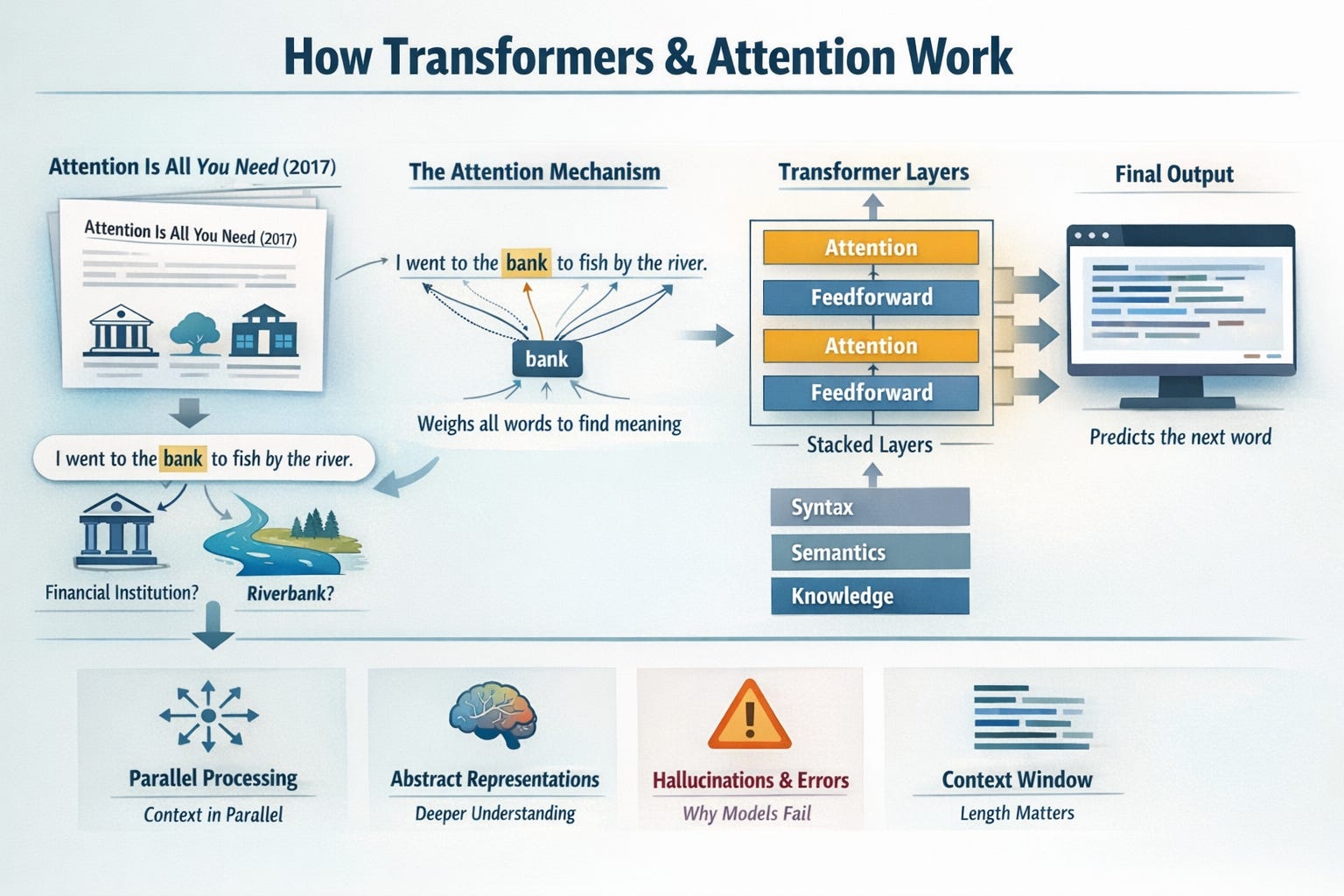
The transformer architecture, introduced in the 2017 paper Attention Is All You Need, is the foundation of every major language model in use today. Understanding it conceptually — not mathematically, conceptually — is the single most important thing you can do before writing your first LLM application.
The key insight is the attention mechanism. When a model processes the word “bank” in a sentence, it needs to determine whether you’re talking about a financial institution or a riverbank. Attention lets the model weigh every other word in the sentence to resolve that ambiguity — it looks at the full context simultaneously rather than reading left to right like older recurrent models did. This parallel processing of context is what makes transformers both powerful and parallelizable at scale.
A transformer is a stack of layers. Each layer runs attention — letting every token look at every other token — followed by a feedforward network that processes each token independently. Stack enough layers with enough parameters, train on enough text, and the model develops increasingly abstract representations of language. The early layers capture syntax. The deeper layers capture semantics, reasoning patterns, and factual associations. What emerges is a model that can generate coherent, contextually appropriate text by predicting the most probable next token at each step.
You don’t need to implement this from scratch to be an effective AI Engineer. But you need the mental model of what’s happening — because it directly explains why these models hallucinate, why they struggle with precise arithmetic, why they’re sensitive to prompt phrasing, and why context window length matters so much.
Tokenization & context windows
Language models don’t read words. They read tokens — chunks of text that may be full words, partial words, or individual characters depending on frequency in the training data. “Unbelievable” might be one token. “GPT” is one token. A rare technical term might be split into four or five tokens. Whitespace and punctuation are tokens too.
This matters practically for several reasons. Token count determines cost — every API call is billed by tokens consumed and generated. Token count determines what fits in the context window — the maximum amount of text the model can “see” at once. And tokenization affects how the model processes certain inputs: numbers, code, and non-English text often tokenize inefficiently, which affects both cost and model performance.
The context window is the model’s working memory. Everything it can attend to — your system prompt, conversation history, retrieved documents, the user’s message — must fit within it. Modern models have large context windows (GPT-4o at 128k tokens, Claude at 200k), but larger context doesn’t mean unlimited. Retrieval performance degrades on very long contexts, latency increases, and cost scales linearly. Understanding context window constraints is fundamental to designing AI applications that work reliably.
Embeddings & semantic meaning
An embedding is a dense numerical vector — typically 768 to 3072 dimensions — that represents the semantic meaning of a piece of text. The key property is that semantically similar texts produce vectors that are close together in this high-dimensional space, even if they share no exact words.
“The patient recovered fully” and “The client made a complete recovery” will produce very similar embeddings despite having almost no word overlap. “The bank approved the loan” and “The bank flooded the road” will produce different embeddings despite sharing the same word, because the surrounding context shifts its meaning.
This is the foundation of semantic search, RAG systems, and clustering-based approaches to text analysis. You’ll use embeddings constantly as an AI Engineer. Develop an intuition for what they represent: a position in meaning-space, not a bag of keywords.
Prompt engineering — zero-shot, few-shot & chain of thought
Prompt engineering is the practice of structuring your inputs to a language model to reliably get the outputs you need. It’s not a soft skill — it’s a technical discipline with measurable impact on performance.
Zero-shot prompting gives the model instructions with no examples. It works well for simple, clearly defined tasks. Few-shot prompting includes examples of the input-output pattern you want, which significantly improves performance on complex or format-sensitive tasks — the model infers the pattern from your examples and applies it.
Chain-of-thought prompting instructs the model to reason step by step before producing a final answer. This is not aesthetic — it materially improves accuracy on reasoning tasks because it forces the model to process intermediate steps rather than pattern-matching directly to an answer. Adding “think step by step” or including a worked example with visible reasoning in your prompt is one of the highest-leverage interventions available for improving output quality.
The meta-skill here is prompt iteration — the ability to identify exactly where a prompt is failing and adjust precisely. Vague instructions produce vague outputs. Specific, constrained, well-exemplified prompts produce reliable outputs. This is an engineering skill, not a creative one.
OpenAI, Anthropic & Gemini APIs
These are the three API providers you’ll work with most. Each has meaningfully different strengths that make them appropriate for different use cases.
OpenAI’s GPT-4o is the most widely integrated model in the ecosystem — the largest number of tools, libraries, and production systems are built on it. It’s a strong default for most tasks. Anthropic’s Claude models have a larger context window, stronger performance on long document tasks and nuanced instruction following, and a different safety profile that matters for certain enterprise use cases. Google’s Gemini has native multimodality and tight integration with Google Cloud infrastructure, which is relevant if your production environment lives there.
Learn the API patterns that are consistent across all three: system prompts vs user messages, temperature and sampling parameters, streaming responses, token counting, and error handling for rate limits and timeouts. These fundamentals transfer directly between providers. The ability to swap providers in your application when pricing, performance, or availability changes is a meaningful architectural advantage.
Open-source models — Llama, Mistral & Qwen
Not every application should use a closed API. Open-source models run on your own infrastructure, which means no data leaves your environment — a requirement for many enterprise and healthcare applications. They also eliminate per-token API costs at scale, which matters when you’re running millions of inferences.
Meta’s Llama 3 family, Mistral’s model series, and Alibaba’s Qwen models are the current leading open-source options. They run locally through Ollama for development and testing. For production, you deploy them on GPU instances through AWS, GCP, or specialized inference providers like Together AI or Fireworks.
The tradeoff is real: open-source models at equivalent parameter counts still lag behind frontier closed models on complex reasoning tasks. But for specific, narrow tasks — classification, summarization of structured documents, code generation in a well-defined domain — a fine-tuned open-source model can match or exceed a closed model while costing a fraction of the price. Knowing when that tradeoff makes sense is a core AI engineering judgment call.
Structured outputs & JSON mode
Production AI applications rarely need free-form prose as output. They need data: a classification label, a list of extracted entities, a filled schema, a structured action plan. Getting language models to reliably output valid, parseable JSON is one of the first practical engineering challenges you’ll encounter.
Most major APIs now support a JSON mode or structured outputs feature that constrains the model’s output to a schema you define. This eliminates malformed JSON and schema mismatches at the API level rather than requiring you to parse and validate downstream. For applications where downstream code depends on structured output — and most production applications do — using schema-constrained generation is not optional.
When native structured output isn’t available, the pattern is: define the schema in your prompt with a clear example, instruct the model to return only JSON with no preamble, and wrap your parsing in try/except with a retry on failure. The retry pattern handles the rare cases where the model still produces malformed output despite clear instructions.
API cost & rate limit management
Running LLM applications at production scale is expensive if you’re not deliberate about it. A single GPT-4o call processing a 10-page document can cost $0.05–0.20. At thousands of calls per day, that compounds quickly.
The practical cost management toolkit: choose model size to match task complexity — GPT-4o-mini or Claude Haiku for simple classification tasks, frontier models only for complex reasoning. Cache responses for identical or near-identical inputs using semantic caching (more on this in the production section). Batch requests when latency tolerance allows. Set token limits on both input and output. Monitor cost per request as a first-class metric from day one.
Rate limits are a separate operational challenge. API providers enforce per-minute and per-day token limits. Production applications need exponential backoff retry logic, request queuing under load, and fallback routing to a secondary provider when primary limits are hit. These aren’t edge cases — they will happen, and handling them gracefully is the difference between a reliable product and one that fails silently under load.
RAG systems
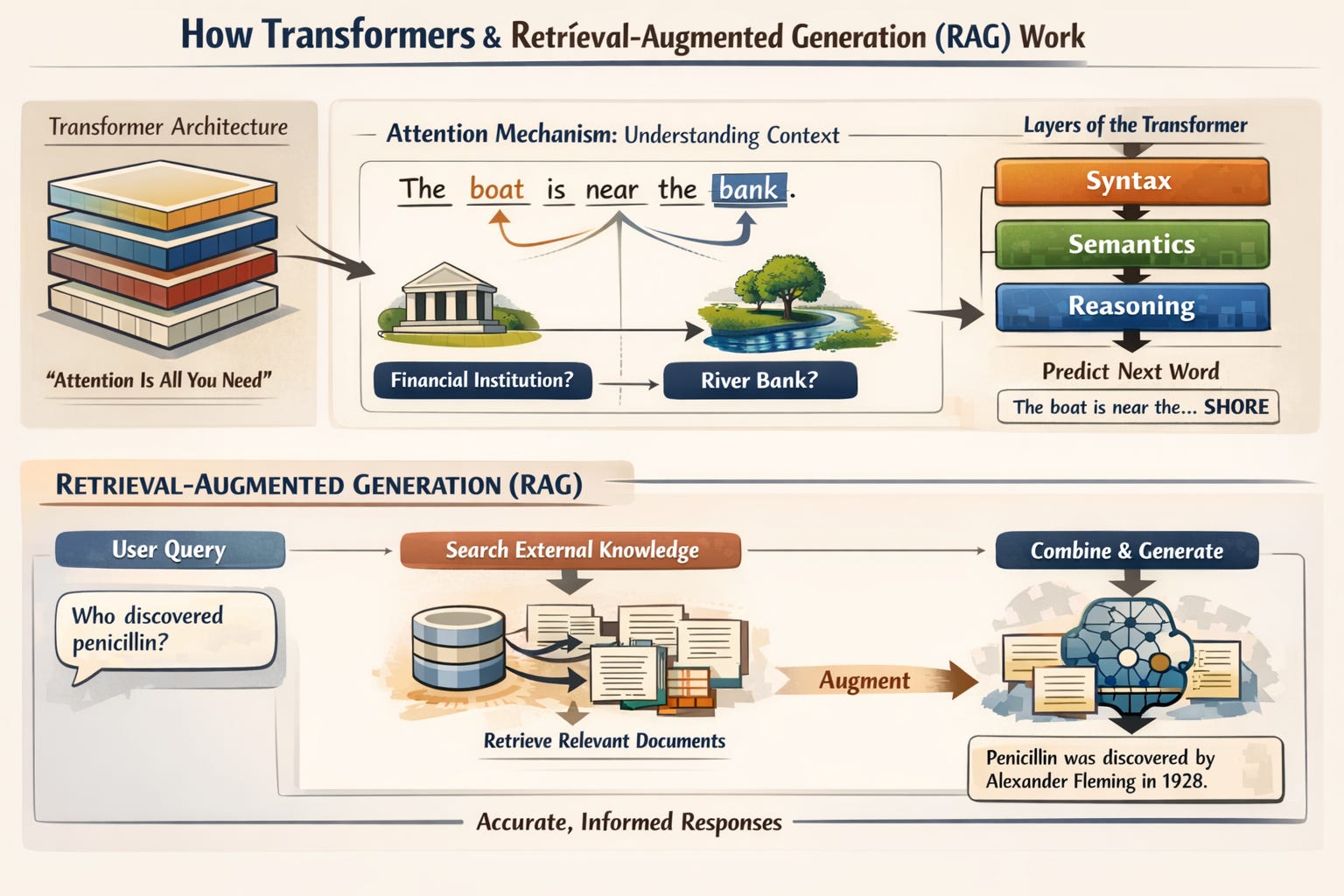
Retrieval-Augmented Generation is the most important architectural pattern in AI engineering right now. The core problem it solves: language models have a training cutoff and a finite context window. They can’t know about your company’s internal documents, last week’s news, or any proprietary information. RAG solves this by retrieving relevant information at query time and injecting it into the model’s context, giving it access to knowledge it was never trained on.
Embeddings & semantic search
Semantic search is the retrieval mechanism that makes RAG work. Instead of searching for keyword matches, you convert both your documents and the user’s query into embedding vectors, then find the documents whose vectors are closest to the query vector in semantic space.
The practical workflow: split your documents into chunks, embed each chunk using an embedding model (OpenAI’s text-embedding-3-small, Cohere’s embed-v3, or an open-source alternative like bge-m3), and store both the chunk text and its vector in a vector database. At query time, embed the user’s question using the same model, compute cosine similarity between the query vector and all stored document vectors, and retrieve the top-k most similar chunks.
The choice of embedding model matters. Different models have different context length limits, dimensionality, and performance characteristics across languages and domains. Run your own benchmark on a representative sample of your actual query-document pairs before committing to an embedding model in production.
Vector databases — Pinecone, Chroma & Weaviate
A vector database stores embeddings alongside their source text and metadata, and provides fast approximate nearest-neighbor search across millions of vectors. This is a fundamentally different operation from traditional database queries — instead of exact matches, you’re finding the geometrically closest points in a high-dimensional space.
Chroma is the right starting point: it runs locally with no setup, integrates cleanly with LangChain and LlamaIndex, and is sufficient for development and small-scale production. Pinecone is the most widely used managed service for production — serverless pricing, simple API, strong performance at scale. Weaviate and Qdrant offer more flexibility and self-hosting options, which matter for privacy-sensitive deployments.
Beyond the vector index, metadata filtering is critical. In a large document store, you often need to restrict retrieval to a subset — documents from a specific time range, a particular source, or a certain category. Most vector databases support metadata filters as part of the similarity search query. Design your metadata schema before you start ingesting data, not after.
Document chunking strategies
How you split documents before embedding them has a larger impact on RAG quality than most beginners expect. Chunks that are too large dilute relevance — the retrieved chunk contains the answer buried in irrelevant surrounding text. Chunks that are too small lose context — a sentence fragment without surrounding context is often uninterpretable.
Fixed-size chunking with overlap is the simplest approach: split every 512 tokens, with 50-100 token overlap between adjacent chunks so no sentence is cut at a boundary. It’s a reasonable default but ignores document structure entirely.
Semantic chunking splits at natural boundaries — paragraph breaks, section headings, sentence boundaries — which preserves coherence. Recursive character text splitting, the approach used by default in LangChain, tries progressively smaller separators until chunks are within the target size. For structured documents like financial reports or technical manuals, hierarchical chunking that preserves the relationship between section headings and their content significantly improves retrieval accuracy.
The right chunking strategy is document-type specific. Run retrieval evals on different chunking approaches before committing to one.
Hybrid search — BM25 + dense retrieval
Pure semantic search has a blind spot: it can miss exact keyword matches that are highly relevant but semantically distant from the query. If a user asks about “LTV:CAC ratio,” a semantic search might return results about customer lifetime value and acquisition strategy — conceptually related but potentially missing documents that use the exact term.
Hybrid search combines dense semantic retrieval with sparse keyword-based retrieval (BM25) and merges the results. BM25 is a classical information retrieval algorithm that scores documents based on term frequency — it excels at exact match and rare term retrieval where semantic search underperforms. Combining both with a reciprocal rank fusion algorithm that merges the two ranked lists consistently outperforms either approach alone.
Most production RAG systems use hybrid search. Weaviate and Qdrant support it natively. For Pinecone, you run BM25 separately and merge results in application code. The implementation overhead is modest and the retrieval quality improvement is consistent enough to justify it as a default.
RAG pipeline evaluation with RAGAS
RAG systems fail in specific, measurable ways. You can’t improve what you can’t measure, and eyeballing outputs is not a measurement strategy.
RAGAS (Retrieval Augmented Generation Assessment) provides a framework for evaluating RAG pipelines on four dimensions: faithfulness (does the answer contain only information supported by the retrieved context?), answer relevance (does the answer actually address the question?), context precision (are the retrieved chunks relevant to the question?), and context recall (were all necessary pieces of information retrieved?). Each metric targets a different failure mode — a pipeline can have perfect retrieval but poor faithfulness if the generator ignores the context, or strong faithfulness but poor context recall if it’s missing key documents.
Build a RAGAS evaluation suite early — before you start optimizing. Define a test set of 50–100 representative questions with known ground truth answers. Run this suite after every significant change to your chunking strategy, embedding model, retrieval parameters, or prompt. Treating RAG evaluation as a continuous measurement process rather than a one-time check is what separates production-quality systems from demos.
Advanced patterns — HyDE, reranking & routing
As your RAG system matures, three advanced patterns consistently deliver meaningful improvements.
HyDE (Hypothetical Document Embeddings) addresses a fundamental mismatch: user queries are short questions, but your document chunks are longer passages. These embed differently even when semantically related. HyDE asks the LLM to generate a hypothetical answer to the query first, then embeds that hypothetical answer rather than the raw query. The hypothetical answer looks more like your document chunks and retrieves more accurately, especially on complex or technical queries.
Reranking adds a second-pass relevance scoring step after initial retrieval. Retrieve 20–50 candidates with your vector search, then run them through a cross-encoder reranker (Cohere’s rerank API or a local model like bge-reranker) that scores each candidate against the query jointly rather than independently. Cross-encoders are slower but significantly more accurate than bi-encoder similarity search. Using them as a reranking step over a larger candidate set gives you both recall and precision.
Query routing is relevant once your knowledge base contains multiple distinct domains. Instead of running every query against your entire vector store, a routing layer classifies the query and directs it to the relevant sub-index. This improves retrieval precision, reduces latency, and makes the system easier to maintain as your knowledge base grows.
AI agents
RAG gives your model access to knowledge. Agents give it access to actions. An AI agent can search the web, run code, call APIs, read and write files, and interact with external systems — not just generate text. This is where AI engineering starts to look like a genuinely new category of software development.
Tool use & function calling
Function calling is the mechanism through which agents interact with the world. You define a set of functions — search the web, query a database, run a calculation, send an email — with their names, descriptions, and parameter schemas. The model reads these definitions and decides which function to call, with what arguments, based on the user’s request. Your code executes the function and returns the result. The model incorporates the result into its next response.
The quality of your function descriptions determines the quality of function selection. A poorly described function will be called in the wrong context or with wrong parameters. Treat function descriptions as a prompt engineering problem: be specific about what the function does, what its parameters mean, when it should and shouldn’t be called, and what it returns. This documentation is read by the model at inference time, not by developers.
Agent memory — short & long-term
A stateless agent that forgets everything between turns is severely limited. Real agents need memory at multiple timescales.
Short-term memory is the conversation history — everything said in the current session. This lives in the context window and is managed automatically when you pass message history to each API call. The challenge is truncation: long conversations eventually exceed the context limit, requiring strategies like summarizing earlier turns and keeping only recent exchanges verbatim.
Long-term memory persists across sessions. The patterns for implementing it: a vector store of past interactions the agent can search semantically, a structured memory object that stores key facts about the user or task as extractable JSON, or a combination. LangGraph, Mem0, and Zep are purpose-built memory systems for agents. The right approach depends on what the agent needs to remember — user preferences, past decisions, factual context about a project.
ReAct loops & planning
ReAct (Reasoning + Acting) is the foundational pattern for agent behavior. The model alternates between two steps: it reasons about what to do next given current information, then acts by calling a tool. The tool result is fed back, the model reasons again, acts again, and continues until it has enough information to produce a final answer.
This loop is deceptively powerful. An agent that can search, read results, reason about what it still needs to know, search again, and synthesize can handle research tasks that would require many separate LLM calls if approached naively. The key engineering challenge is loop termination — defining clear stopping conditions and maximum iteration limits to prevent infinite loops when the model gets confused about task completion.
Planning is the more structured cousin of ReAct. Before acting, the model produces an explicit plan — a numbered list of steps — and then executes each step. Planning improves performance on tasks that require multiple sequential operations because it forces the model to think through dependencies before starting.
LangGraph, CrewAI, AutoGen & Agno
The agent framework landscape is crowded and evolving fast. Understanding what each tool is actually for prevents the common mistake of using a complex multi-agent framework when a simple ReAct loop would have been sufficient.
LangGraph is the most production-ready option for building stateful, controllable agents. It models agent behavior as an explicit graph of nodes and edges, giving you full control over the execution flow, state transitions, and error handling. The explicitness makes it debuggable in a way that more magical frameworks are not. Start here for anything going to production.
CrewAI and AutoGen are designed for multi-agent workflows where different agents have different roles and collaborate on a task. CrewAI’s role-based abstraction is intuitive — you define a researcher, a writer, a reviewer — but the abstraction can obscure what’s actually happening. AutoGen is Microsoft’s offering with stronger code execution capabilities. Both are appropriate for prototyping multi-agent pipelines but require careful evaluation before production deployment.
Agno is a newer, lightweight framework focused on performance and simplicity. Worth knowing, especially for applications where inference speed and low overhead matter.
Multi-agent orchestration patterns
A single agent calling tools sequentially is the simplest pattern and handles most use cases. Multi-agent systems are warranted when tasks can be genuinely parallelized, when different subtasks require different specialized tools or personas, or when the complexity of a single agent’s prompt would become unmanageable.
The most important pattern to understand is the orchestrator-worker model. An orchestrator agent receives the high-level task, decomposes it into subtasks, dispatches each to a specialized worker agent, and synthesizes the results. The orchestrator doesn’t do the work — it coordinates. Worker agents are narrow, specialized, and don’t need to understand the full context of the task.
The practical risk of multi-agent systems is error propagation. A mistake in a worker agent’s output, uncaught by the orchestrator, compounds through subsequent steps. Build explicit validation between agent handoffs and log every inter-agent message. Debugging a multi-agent pipeline without logs is nearly impossible.
Agent evaluation & debugging
Agents are harder to evaluate than standard ML models because their behavior is sequential, stochastic, and involves tool calls with real-world side effects. A single incorrect tool call can derail an entire multi-step task. Standard accuracy metrics don’t capture this.
Evaluate agents on task completion rate — did the agent accomplish the stated goal end-to-end? — and separately on trajectory quality — did it take an efficient, sensible path to get there? An agent that completes a task in twelve tool calls when four would have sufficed is behaving poorly even if the final output is correct.
For debugging, trace logging is non-negotiable. Log every reasoning step, every tool call with its parameters and return value, and every decision point. LangSmith’s tracing integration with LangChain and LangGraph provides this out of the box. Without traces, debugging agent failures is guesswork.
Fine-tuning & optimization
Prompt engineering gets you far. Fine-tuning takes you further — but only in the right circumstances. This section is about understanding when fine-tuning is the right tool, and how to do it without wasting compute and money.
When to fine-tune vs prompt engineer
This is the most important question in this section and the one most people get wrong. Fine-tuning is not the first resort when a model isn’t behaving the way you want. It’s the last resort after prompt engineering, few-shot examples, and RAG have been genuinely exhausted.
Fine-tune when you need consistent stylistic behavior that prompt engineering can’t reliably enforce — a specific tone, a domain-specific vocabulary, a precise output format. Fine-tune when you have a narrow, well-defined task with hundreds or thousands of high-quality examples. Fine-tune when you need to reduce latency and cost by using a smaller base model that matches a larger model’s performance on your specific task.
Don’t fine-tune to inject new factual knowledge — that’s what RAG is for. Don’t fine-tune when you don’t have high-quality labeled data. Don’t fine-tune as an alternative to writing a good system prompt. The compute cost, infrastructure complexity, and ongoing maintenance of fine-tuned models are real — make sure the performance gain justifies them.
LoRA & QLoRA methods
Full fine-tuning updates all of a model’s parameters — for a 7B parameter model, that means updating seven billion weights every training step. This requires massive GPU memory and is prohibitively expensive for most practitioners.
LoRA (Low-Rank Adaptation) is the solution that made fine-tuning accessible. Instead of updating all parameters, LoRA freezes the original model weights and adds small trainable matrices alongside specific layers. These adapter matrices have dramatically fewer parameters than the full model — often less than 1% — but capture the adaptation needed for your task. The original model is untouched and can be reused for other tasks.
QLoRA extends this further by quantizing the base model to 4-bit precision before adding LoRA adapters. This reduces memory requirements dramatically — a 7B model that would require 28GB of GPU memory at full precision fits in under 6GB with QLoRA. This makes fine-tuning possible on a single consumer GPU or an affordable cloud instance. QLoRA is the default approach for most practitioners and produces results competitive with full fine-tuning on most tasks.
PEFT & parameter-efficient training
PEFT (Parameter-Efficient Fine-Tuning) is the umbrella term for the family of techniques that includes LoRA, QLoRA, and related methods. The Hugging Face PEFT library is the standard implementation — it integrates with Transformers and provides a consistent interface for applying different PEFT methods.
Beyond LoRA, prefix tuning and prompt tuning are worth knowing conceptually. Prefix tuning prepends trainable tokens to the model’s input at each layer. Prompt tuning (not to be confused with prompt engineering) learns soft, continuous prompt tokens in the embedding space. Both are more parameter-efficient than LoRA but generally underperform it on most tasks. LoRA and QLoRA are the practical defaults — understand the others to contextualize why.
Dataset curation for fine-tuning
The quality of your fine-tuning dataset matters more than the size. A thousand high-quality, diverse, correctly formatted examples consistently outperforms ten thousand noisy or inconsistent ones. Data quality is not something you can compensate for with more training steps.
Each example should be an input-output pair that represents the exact behavior you want the model to learn. The inputs should cover the realistic distribution of queries the model will receive in production. The outputs should be the gold standard responses you want — written carefully, consistently formatted, and free of contradictions.
Common pitfalls: training on data that doesn’t reflect production inputs, including examples where the correct answer isn’t actually what you want the model to do, and underrepresenting difficult or edge case inputs. Reserve 10–15% of your data as a held-out evaluation set before you begin training, and don’t look at it until you have a model you’re considering deploying.
DPO & preference optimization
Supervised fine-tuning trains the model to produce a specific output given an input. Preference optimization trains the model to prefer certain outputs over others — a subtler and often more effective approach for tasks where “correct” is difficult to define absolutely.
DPO (Direct Preference Optimization) is the current standard method. For each training example, you provide the model with a prompt and two responses — a preferred one and a rejected one — and train the model to increase the probability of the preferred response relative to the rejected one. This is particularly effective for improving output quality on open-ended tasks like writing, summarization, and instruction following where a single correct answer doesn’t exist.
Collecting preference data requires human labelers or a strong teacher model rating your outputs. If you’re using a teacher model (often called AI feedback), evaluate the consistency of its ratings carefully — inconsistent preference labels produce inconsistent model behavior.
Benchmark-based evaluation
Before you deploy a fine-tuned model, you need to know it’s actually better than the base model on your task and hasn’t degraded on tasks you care about. Eyeballing outputs is not sufficient.
Build a task-specific evaluation benchmark from your held-out test set. Define metrics that match your actual quality criteria: exact match for structured output tasks, ROUGE or BERTScore for summarization, custom rubric-based LLM scoring for open-ended generation. Run your fine-tuned model and the base model on the same benchmark and compare.
Also run standard capability benchmarks to check for regression. Fine-tuning can cause catastrophic forgetting — the model overspecializes on your task and loses general capabilities. If your production application uses the model for multiple tasks, this matters. Monitoring performance across a broader benchmark set before deployment catches regressions before your users do.
Production AI systems & LLMOps

Getting an LLM feature to work in a demo is easy. Running it reliably under real user load, at predictable cost, with visibility into failures, for months — that’s the engineering problem. This section covers everything between a working prototype and a trustworthy production system.
LLMOps platforms — LangSmith, Arize & Phoenix
LLMOps is the operational discipline of managing language model applications in production. The tooling has matured rapidly and there are now purpose-built platforms that handle tracing, evaluation, monitoring, and prompt management in one place.
LangSmith is the most widely adopted, especially in teams already using LangChain or LangGraph. It captures full execution traces — every LLM call, every tool invocation, latency, token counts, and costs — and provides a UI for browsing, filtering, and debugging them. It also integrates evaluation pipelines directly so you can run automated quality checks against your trace data.
Arize and Phoenix are stronger for teams that need model monitoring beyond LLMs — if you’re running a combination of classical ML models and LLM-based features, Arize provides a unified observability layer. Phoenix is open-source and self-hostable, which matters for data-sensitive environments. Know all three exist, start with LangSmith for most use cases, and evaluate alternatives based on your specific data governance and infrastructure requirements.
Latency optimization & semantic caching
User tolerance for latency is low and LLM inference is inherently slow relative to traditional APIs. Optimization is not optional for user-facing applications.
The highest-leverage interventions in order of impact: use streaming to return tokens as they’re generated rather than waiting for the full response — this dramatically improves perceived performance even when total latency is unchanged. Choose the smallest model that meets your quality bar for each task — GPT-4o-mini is 10–20x cheaper and faster than GPT-4o with comparable quality on many tasks. Use asynchronous calls when your application makes multiple independent LLM requests — run them in parallel rather than sequentially.
Semantic caching goes further. Instead of caching only exact duplicate requests, a semantic cache retrieves cached responses for queries that are semantically similar above a threshold — “what’s your return policy” and “how do I return an item” get the same cached response. GPTCache and Redis with vector search both support this pattern. Cache hit rates of 20–40% are typical in production chatbots and translate directly to cost and latency savings.
Cost management & batching strategies
LLM costs at scale are real and poorly understood until a bill arrives. The framework for managing them: measure cost per request and cost per user as first-class metrics from day one, not as an afterthought when the invoice surprises you.
Batching is the highest-leverage cost reduction strategy for asynchronous workloads. If you’re running document summarization, data extraction, or content moderation at scale without real-time latency requirements, batch API endpoints (available from OpenAI and Anthropic) run requests at 50% of standard pricing with 24-hour turnaround. For background jobs, this is a straightforward cost halving with minimal engineering effort.
Prompt optimization reduces costs at the input level. Audit your system prompts for redundancy — verbose prompts with repeated instructions cost more without producing better results. Use the minimum number of few-shot examples needed to achieve your quality bar. Compress retrieved context before injection — summarize or truncate chunks that are only marginally relevant. These micro-optimizations compound at scale.
Safety, evals & guardrails
Production AI applications need guardrails — mechanisms that catch and handle undesirable model behavior before it reaches users. This includes off-topic responses, harmful content, hallucinated factual claims, prompt injection attacks, and PII leakage.
Input guardrails validate or classify user inputs before they reach your LLM. Output guardrails validate model responses before they’re returned to users. LlamaGuard, Guardrails AI, and NeMo Guardrails are purpose-built for this. For simpler use cases, a secondary LLM call that classifies the primary model’s output as acceptable or not — with a fallback response when it isn’t — is often sufficient.
Evals are your automated quality assurance system. Define a test suite of inputs with expected outputs or evaluation criteria, and run it on a schedule and after every significant change. The eval suite should cover your best cases (where the system should definitely work), your edge cases (inputs that have historically caused problems), and your adversarial cases (attempts to break the system). Treat a failing eval as a breaking build.
Prompt versioning & A/B testing
Prompts are code. They need version control, change management, and controlled deployment. Editing a system prompt directly in production without testing is the LLM equivalent of deploying untested code to production.
Store prompts in your version control system or in a prompt management platform like LangSmith. Every change gets a version number and a changelog entry. Test prompt changes against your eval suite before promoting them. When you’re uncertain between two prompt versions, run an A/B test — split traffic between them, collect outcome metrics for each, and promote the winner based on data rather than intuition.
The subtlety with prompt A/B testing is defining the right metric. Token count and latency are measurable automatically. Quality requires either human evaluation or an LLM-as-judge setup where a secondary model scores responses. Both are valid — the choice depends on your traffic volume and quality tolerance.
Observability, tracing & structured logging
You cannot debug what you cannot observe. In traditional software, logs tell you what happened. In LLM applications, traces tell you why — the full sequence of reasoning steps, tool calls, retrieved documents, and model decisions that produced a given output.
Structured logging means every LLM interaction writes a machine-parseable record: timestamp, session ID, model version, prompt version, input token count, output token count, latency, cost, tool calls made, and the raw input and output. This data is the foundation of every other operational capability — cost analysis, quality monitoring, debugging, and evaluation all depend on it.
Distributed tracing connects logs across multiple services. When a user request triggers an agent that calls three tools, makes two LLM calls, and writes to a database, a trace links all of these events into a single timeline with a shared request ID. Without this, debugging a multi-step agent failure means manually correlating logs across multiple services by timestamp. OpenTelemetry is the standard for instrumentation and integrates with LangSmith and Arize for AI-specific visualization. Instrument your application from the first day of production deployment — retrofitting observability is painful and you will always wish you had it sooner.
AI Projects for Portfolio
1. RAG chatbot over a private document library
Stack: Python, LangChain, OpenAI API, Chroma, FastAPI, Streamlit, Docker
The canonical first RAG project — and the one that appears most frequently in AI engineering job descriptions. The goal is a chatbot that answers questions accurately using a private document set it was never trained on.
Use a meaningful document collection: a set of research papers, a company’s public documentation, a collection of legal contracts, or a set of product manuals. Ingest documents through a preprocessing pipeline that handles PDF parsing, text extraction, and metadata tagging by source and date. Chunk with overlap using recursive character splitting, embed with OpenAI’s text-embedding-3-small, and store in Chroma.
The work that elevates this beyond a tutorial is the evaluation layer. Build a RAGAS test suite with 50 hand-crafted question-answer pairs drawn from your documents. Run baseline retrieval, measure faithfulness and answer relevance scores, then iterate — try different chunk sizes, overlap ratios, and top-k values and document the impact of each change on your eval scores. Ship a Streamlit front-end that shows the user not just the answer but the retrieved source chunks with relevance scores, so the system’s reasoning is transparent. Source attribution is what makes RAG trustworthy rather than just impressive.
2. Hybrid search knowledge base with reranking
Stack: Python, FastAPI, Qdrant, BM25 (rank-bm25), Cohere Rerank API, LangChain, Streamlit
Most RAG tutorials implement pure vector search and call it done. This project demonstrates that you understand the full retrieval stack — and that you can measure the difference each component makes.
Index the same document set using two parallel systems: a Qdrant vector index for dense semantic retrieval and a BM25 index for sparse keyword retrieval. At query time, retrieve the top-20 candidates from each, merge with reciprocal rank fusion, and pass the merged set through Cohere’s reranking API to produce a final top-5. Feed these into an LLM for answer generation.
The deliverable that makes this stand out is the comparison dashboard. Build a Streamlit interface with three tabs: dense only, BM25 only, and hybrid with reranking. Run the same query through all three and display the retrieved chunks and final answers side by side. Include your RAGAS scores for each configuration. This is a project that teaches something to the person reviewing it — and portfolio projects that teach something are memorable.
3. Multi-modal RAG system over documents with tables & images
Stack: Python, LangChain, OpenAI GPT-4o, Unstructured.io, Chroma, FastAPI, Streamlit
Text-only RAG fails on a large class of real documents: PDFs with embedded charts, tables, diagrams, and mixed layouts. This project addresses that gap and demonstrates awareness of a production pain point that most RAG tutorials completely ignore.
Use Unstructured.io to parse complex PDFs — financial reports, research papers, technical datasheets — extracting text, tables as structured objects, and images as separate elements. Embed text chunks and table summaries using a text embedding model. For images and diagram-heavy pages, use GPT-4o’s vision capability to generate a textual description of the visual content, then embed that description. Store all element types in Chroma with metadata indicating their element type.
At retrieval time, run the query against all element types and let the reranker surface the most relevant regardless of modality. When a retrieved element is an image or table, pass it directly to GPT-4o alongside the query for interpretation. The interesting eval question to answer in your README: on what query types does multi-modal retrieval outperform text-only retrieval, and by how much? Answering this with data rather than assertion is what makes the project credible.
4. Autonomous research agent
Stack: Python, LangGraph, OpenAI API, Tavily Search API, LangSmith, FastAPI, Streamlit
This is the agent project that most directly maps to a production use case. Given a research question — “what are the main approaches to reducing hallucination in LLMs?” or “summarize the competitive landscape for vector databases” — the agent searches the web, reads and synthesizes sources, identifies gaps in its knowledge, searches again, and produces a structured report with citations.
Build the agent as a LangGraph state machine with explicit nodes: a planning node that decomposes the question into sub-questions, a search node that queries Tavily for each sub-question, a reading node that fetches and summarizes full pages from the top results, an evaluation node that assesses whether the collected information is sufficient to answer the original question, and a synthesis node that writes the final report. The evaluation node is what prevents the agent from stopping too early or looping indefinitely — it’s the most important piece of engineering in the project.
Instrument every node with LangSmith tracing. Your README should include a full trace walkthrough of a sample research task showing exactly what the agent did at each step, what it retrieved, and what decisions it made. This trace-based documentation is itself a portfolio artifact that demonstrates operational maturity.
5. Customer support agent with escalation routing
Stack: Python, LangGraph, OpenAI API, Pinecone, FastAPI, PostgreSQL, Redis, Docker
This project simulates a production AI Engineering deployment more closely than almost any other. Customer support is the most common first production use case for LLM agents, and the engineering challenges it presents — intent classification, knowledge retrieval, tool use, session memory, escalation logic, and compliance — are directly transferable across industries.
Build a LangGraph agent with four capabilities: answering questions using RAG over a product knowledge base, performing account lookups through a mock API tool, processing simple requests like order status or refund initiation through structured tool calls, and escalating to a human when confidence is low or the request falls outside its defined scope. The escalation logic is the critical engineering decision — define explicit conditions under which the agent should not attempt to resolve a request, and make those conditions configurable without redeployment.
Implement session memory using Redis for short-term conversation state and PostgreSQL for long-term customer interaction history. Every conversation is logged with full traces. Build a simple operator dashboard in Streamlit that shows live conversations, flags low-confidence interactions, and displays the agent’s reasoning chain for any message. The dashboard turns this from a chatbot into an observable system — exactly the distinction that matters in production.
6. LLM-powered data extraction pipeline
Stack: Python, OpenAI API (structured outputs), Pydantic, Prefect, PostgreSQL, FastAPI, Docker
Unstructured data extraction is one of the highest-ROI applications of LLMs in enterprise settings. This project builds a pipeline that takes raw unstructured documents — contracts, invoices, medical notes, job descriptions — and extracts structured data into a defined schema, reliably and at scale.
Define a Pydantic schema for your target document type. For contracts: parties, effective date, termination clauses, payment terms, governing law, key obligations. For invoices: vendor, line items, amounts, due date, payment method. Use OpenAI’s structured outputs feature to constrain the model’s response to your schema, eliminating parse errors entirely.
The production engineering work is the pipeline: a Prefect flow that watches an S3 bucket for new documents, runs extraction, validates the output against business rules (amounts must be positive, dates must be parseable, required fields must be present), writes valid extractions to PostgreSQL, and routes invalid ones to a human review queue with the specific validation failure flagged. Track extraction accuracy on a held-out labeled test set. Document your accuracy by document type and field — some fields extract reliably, others don’t, and knowing which is which is the insight a production team needs.
7. Fine-tuned domain-specific model on HuggingFace
Stack: Python, HuggingFace Transformers, PEFT, QLoRA, bitsandbytes, Weights & Biases, Google Colab or RunPod
Fine-tuning is the project most AI engineers say they know how to do and few actually have done end-to-end. This project closes that gap and produces a published artifact — a HuggingFace model card — that is visible and verifiable.
Choose a narrow, well-defined task where a fine-tuned smaller model can match a larger model’s performance: medical question answering, legal clause classification, SQL generation from natural language, or code review comment generation. Curate or generate 500–2000 high-quality instruction-following examples in the system/user/assistant format. Split 85/15 for train and evaluation.
Apply QLoRA to a Llama 3 8B or Mistral 7B base using the HuggingFace PEFT library. Train on a Colab A100 or a RunPod GPU instance — document the exact compute cost in your README. Track every training run in Weights & Biases, including loss curves, learning rate schedule, and evaluation metrics at each checkpoint. Run the fine-tuned model and the base model through an identical evaluation benchmark and publish both sets of numbers.
Push the final model to HuggingFace with a detailed model card: task description, training data description, training procedure, evaluation results, intended use, and limitations. A published model card with honest evaluation numbers is a more credible portfolio signal than a GitHub repo with claimed but unverifiable performance.
8. AI coding assistant with codebase RAG
Stack: Python, LangChain, OpenAI API, Tree-sitter, Chroma, FastAPI, VS Code extension (optional)
This project is both technically sophisticated and immediately useful — you’re building a tool you’ll actually use. The goal is a coding assistant that understands a specific codebase and can answer questions about it, explain functions, suggest implementations, and identify relevant files for a given task.
The retrieval challenge is different from document RAG. Code has structure that plain text doesn’t: functions, classes, imports, call graphs. Use Tree-sitter to parse the codebase into an abstract syntax tree, extract individual functions and classes as discrete chunks with their full context (file path, class membership, docstrings, imports used), and embed each at the function level rather than by line count. This preserves semantic units that chunking by character count would split.
Add a call graph index alongside the vector index. When a user asks about a function, retrieve not just that function but its callers and callees. This context — where is this function used, and what does it call — is often more useful for understanding code than the function body alone.
Build a FastAPI backend and a simple CLI or VS Code extension as the interface. Evaluate on a test set of questions about your indexed codebase where you know the ground truth answers. The README should include an architecture diagram of the indexing pipeline and a comparison of function-level chunking versus line-based chunking on retrieval accuracy.
9. Multi-agent content pipeline
Stack: Python, LangGraph, OpenAI API, Tavily Search API, LangSmith, Streamlit, PostgreSQL
Multi-agent systems are most justified when different subtasks require genuinely different capabilities or when parallelization meaningfully reduces latency. Content generation pipelines satisfy both conditions — and this project demonstrates you can architect a multi-agent system with clear role separation rather than just bolting agents together arbitrarily.
Build an orchestrator-worker pipeline for long-form content generation. Given a topic and target audience, the orchestrator decomposes the task and dispatches to four specialized workers: a research agent that uses Tavily to gather current information and statistics, an outline agent that structures the content based on the research, a writing agent that drafts each section, and an editor agent that reviews the draft for factual consistency with the research, tonal consistency, and structural coherence. The orchestrator collects outputs, resolves conflicts between agents, and assembles the final piece.
The engineering decisions worth documenting: how does the orchestrator handle a worker returning low-confidence output? What’s the retry strategy when the writing agent produces a section that the editor agent rejects? How do you pass context efficiently between agents without blowing the context window? These architectural decisions are what make the README worth reading. Log every inter-agent message through LangSmith and include a trace walkthrough for a sample content generation run.
10. Production LLMOps platform with full observability
Stack: Python, LangGraph, LangSmith, FastAPI, PostgreSQL, Grafana, Prometheus, Docker Compose, OpenAI API, Evidently AI
This is the capstone AI engineering project — the equivalent of the MLOps monitoring system on the ML side. It doesn’t showcase the most impressive model behavior, but it showcases the most impressive engineering, and that distinction matters at the senior level.
Build a production-grade LLM application — a domain-specific Q&A system or a document processing pipeline — with a complete operational layer around it. Every LLM call is traced through LangSmith with full input, output, latency, token count, and cost logged. Every trace is also written to PostgreSQL as a structured record for long-term analysis.
Prometheus scrapes operational metrics — request rate, error rate, p50/p95/p99 latency, cost per request — and Grafana visualizes them in a live dashboard. Evidently AI runs on a schedule computing drift reports: are the input queries shifting in topic distribution over time? Are output lengths changing? Are confidence scores degrading?
Add a prompt A/B testing framework: define experiment configurations in a YAML file, split traffic between prompt variants at the application layer, and surface results in a separate Grafana panel showing quality metrics by variant. Build a one-command rollback that reverts to a previous prompt version if the active variant’s quality score drops below a threshold.
Document every architectural decision in the README with the reasoning behind it. Include a section on what you would add with more time and what you would do differently. This kind of reflective technical writing is rare in portfolios and signals the kind of engineering maturity that senior roles require.
Where to go from here
You’ve just read through one of the most comprehensive breakdowns of the ML and AI Engineering landscape available anywhere. The role definitions, the curriculum, the projects, the tooling — all of it maps to what companies are actually hiring for right now, not what was relevant three years ago.
But a breakdown is not a plan. And a plan without structure is just good intentions.
The gap between people who read roadmaps and people who actually land the role isn’t talent. It isn’t even time. It’s the difference between knowing what to learn and having a clear, sequenced system that tells you exactly what to do next — so you never open your laptop and wonder where to start.
That’s what the AI Engineer Roadmap is built for.
It takes everything covered in the AI Engineering track of this guide — LLM fundamentals, RAG systems, agents, fine-tuning, production LLMOps — and turns it into a step-by-step learning path with project milestones, resource recommendations, and a structured progression from zero to job-ready. No guessing about sequencing. No wasted weeks going deep on something that doesn’t move the needle. No more jumping between YouTube tutorials and hoping the pieces connect.
Over 100 people have used frameworks like this to land roles at companies including Google, Microsoft, Airbnb, and Anthropic. The roadmap isn’t magic — the work is still yours to do. But having the right map makes the work count.
If you’re serious about breaking into AI Engineering in 2025–2026, this is the clearest path forward I know of.
The window for getting into this field ahead of the curve is still open. It won’t be forever.